How do modern AI search engines and LLMs operate and how do you optimize for them?

This isn’t 2015 anymore, yet some SEO “experts” are still clinging to tactics like they’re waiting for Windows 7 to make a comeback. Modern AI-powered search engines and large language models (LLMs) leverage Retrieval-Augmented Generation (RAG) to combine external data retrieval with text generation, ensuring answers are both current and contextually accurate. By performing a real-time search of trusted documents before crafting a response, these systems mitigate outdated training data and “hallucinations.” To optimize for them, create clear, structured content with up-to-date citations, conversational Q&A headings, and appropriate schema markup, so AI retrieval steps can easily identify and quote your material.
Key Takeaways
-
- RAG enables AI to fetch and ground answers in fresh, external sources.
- RAG enables AI to fetch and ground answers in fresh, external sources.
-
- Structured Q&A headings and bullet points improve AI snippet retrieval.
- Structured Q&A headings and bullet points improve AI snippet retrieval.
-
- Embedding authoritative, date-stamped references boosts trust signals.
- Embedding authoritative, date-stamped references boosts trust signals.
-
- Conversational phrasing and varied keywords aid vector-based matching.
- Conversational phrasing and varied keywords aid vector-based matching.
-
- Schema markup (FAQPage, HowTo) helps AI isolate self-contained snippets.
- Schema markup (FAQPage, HowTo) helps AI isolate self-contained snippets.
-
- Off-page promotion can still surface in AI searches.
-
- Optimizing content for RAG-driven AI results increases probability to appear in AI summaries and chatbot responses, giving you traffic that static search rankings might miss.
Detailed Guide
What is Retrieval-Augmented Generation (RAG) in simple terms?
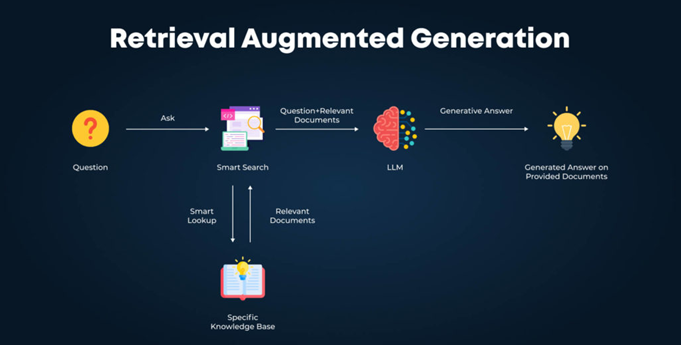
Retrieval-Augmented Generation (RAG) is a hybrid AI workflow that enhances language models by letting them “look up” relevant documents at query time, rather than relying solely on what they learned during pretraining. Imagine asking a librarian to fetch the latest journal article before answering your question; RAG works similarly. Except this librarian is more like Alexa or Siri than your stereotypical Miss Finster.
When you submit a query, the system first searches an external data source, such as a website index, a private knowledge base, or a specialized dataset of academic papers, for pertinent passages. Then, it feeds those retrieved snippets into the LLM as additional context, guiding the generative process so the answer is grounded in factual, up-to-date material. This approach addresses two major limitations of standard LLMs: information cutoff dates and the risk of “hallucinations,” where the model invents plausible-sounding but incorrect details.
How does the retrieval phase work?
-
- User Query Submission
You ask a question—e.g., “What are the 2025 tax deadlines for small businesses in Texas?” The RAG-enabled system takes this natural-language query as input.
- User Query Submission
-
- External Search
Instead of directly generating an answer from pretraining data, the system performs a search against an external document collection, which could be a public web index, a company’s internal file repository, or a specialized dataset of academic papers (AWS, 2024; WEKA, 2025).
- External Search
-
- Result Ranking
Retrieved documents or text snippets are ranked by relevance using vector similarity, which transforms both the query and documents into numerical embeddings, or traditional keyword-based matching. The top N results (often broken into smaller “chunks” of text) are selected based on how closely they align with the user’s question.
- Result Ranking
-
- Outcome
At the end of this phase, the system holds a set of highly relevant, often date-stamped passages that directly address the query.
- Outcome
How does the augmentation and generation phase work?
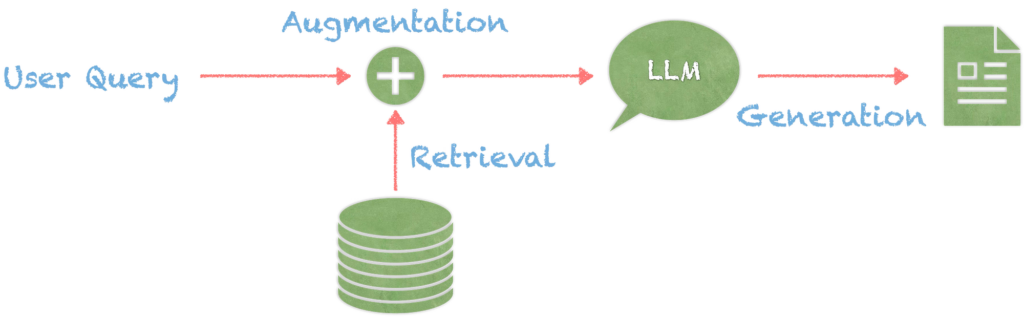
-
- Context Assembly
The RAG engine takes the top-ranked snippets—sometimes as short as a few sentences each—and concatenates them with the original user query. This assembled context is fed into the LLM.
-
- Guided Response Generation
Rather than “freewriting” from its pretraining knowledge, the LLM now “reads” the assembled context and composes an answer that weaves together facts from the retrieved snippets with its own linguistic patterns. It essentially uses the retrieved passages as anchors, ensuring that every factual statement can be traced back to a specific external source.
-
- Optional Citation Insertion
Some RAG implementations explicitly insert inline citations or footnotes, indicating which document or page each fact originates from. This enhances transparency and credibility, especially in domains like healthcare or legal research.
-
- Outcome
The final output is a coherent, conversational response that is both fluent and verifiably sourced—reducing the likelihood of “hallucinations”.
Why does RAG matter?
-
- Accuracy and Currency
Because RAG fetches fresh data at query time, it can provide up-to-the-minute answers—even if the underlying LLM was last trained months or years ago. For example, a healthcare AI using RAG can retrieve the latest CDC guidelines before generating a recommendation, rather than relying on outdated training data.
-
- Reduced Hallucinations
By grounding responses in concrete, external sources, RAG dramatically lowers the risk of fabricated or misleading information. When users see inline citations, trust in AI-generated answers increases.
-
- Domain Specialization
Organizations can connect RAG systems to highly specialized knowledge bases—like a law firm’s case archives or a manufacturer’s product specs—without retraining the LLM. The AI becomes an expert in that domain simply by accessing the right repository at query time.
-
- Cost Efficiency
Instead of fine-tuning a massive LLM every time new information is added, you update the external datastore. This “decoupling” of model training from content updates is faster, cheaper, and more scalable—especially for companies that produce time-sensitive reports or whitepapers.
-
- Competitive Differentiation
As Google’s “AI Mode” is rolled out on a more massive scale, organizations that optimize for RAG-driven visibility gain a strategic edge. Their content is more likely to be surfaced in AI-generated summaries and chatbot answers, capturing traffic that might otherwise bypass static search engine results.
How to optimize content for RAG-driven AI search engines?

Optimizing for RAG workflows means ensuring your content is structured, authoritative, and easy for retrieval algorithms to pinpoint. Below are actionable tactics:
1. Craft Clear, Structured, Answer-Focused Content
AI retrieval steps look for self-contained “snippets” that directly match user queries. Use semantic headings for primary sections so AI bots can isolate exact sections to quote. Begin each section with a concise answer.
For example:
How to File Sales Tax in California (2025 Update)
As of June 2025, all California small businesses must file sales tax returns by the 15th of each month. Refer to the California Department of Tax and Fee Administration website for exact forms.
-
- Use bullet lists and numbered steps for procedures to enhance snippet eligibility.
-
- Include a “TL;DR” summary at the top of long articles so RAG systems can grab that concise overview.
2. Embed Up-to-Date, Authoritative References
RAG systems ground their output in trusted documents. Pages that cite reputable, recent sources—such as government websites, peer-reviewed journals, or industry white papers—signal higher trustworthiness.
-
- Link to the latest guidelines or studies with a clear “Last Updated” date.
-
- Regularly audit and update publication dates to maintain freshness, benefiting both human readers and AI bots.
Example:
“According to the CDC’s May 2025 update on COVID-19 guidelines, mask mandates for healthcare workers in high-risk settings remain in effect (CDC, May 2025).”
3. Use Conversational Phrasing and Natural-Language Keywords
RAG retrieval often relies on vector-based similarity, matching semantic meaning rather than exact keywords. Write headings as questions users would ask—e.g., “What Are the 2025 Tax Deadlines for Freelancers in Texas?”—and follow with an immediate, concise answer.
-
- Include synonyms and related terms, such as “self-employed tax due dates” and “independent contractor tax deadlines,” to create multiple semantic entry points.
-
- Adopt a conversational tone so your content aligns with how AI systems interpret queries, boosting retrieval probability.
4. Leverage Schema Markup and FAQ/HowTo Blocks
Structured data markup—like FAQ Page or How To schema—helps AI crawlers precisely identify Q&A pairs and step-by-step instructions.
-
- Wrap each Q&A pair in FAQ Page JSON-LD so RAG systems know these are self-contained snippets.
-
- Use How To schema for multi-step guides, clearly delineating each step.
When Google’s AI Mode or other RAG-enabled platforms crawl your page, they can directly parse these structured blocks without scanning raw text.
5. Build Topical Authority and Maintain a Clean Technical Foundation
RAG systems prefer content from authoritative domains with strong topical clusters.
-
- Publish comprehensive guides that interlink subtopics, demonstrating subject-matter depth.
-
- Acquire backlinks from reputable industry publications—these act as trust signals in both traditional SEO and AI retrieval scoring.
-
- Optimize technical SEO: ensure fast page load times, mobile responsiveness, secure HTTPS hosting, and accurate XML sitemaps so crawlers can index every relevant page.
Tip: Use tools like Google Search Console to verify your sitemap and crawling status. If pages are excluded, AI retrieval systems won’t be able to find your snippets, regardless of content quality.
6. Monitor and Adapt to AI Search Analytics
Once your content is live, track AI-driven search performance via analytics platforms that show which snippets are being cited in chatbot outputs or AI summaries.
-
- Review query logs to identify gaps and update content accordingly.
-
- Refresh your knowledge base and schema markup periodically to keep pace with algorithmic changes.
By treating optimization as an ongoing process rather than a one-time project, you ensure continual visibility in evolving RAG-driven ecosystems.
7. Incorporate Off-Page SEO And PR Tactics for AI Visibility
Traditional digital PR often promoted press releases, link-building or aggressive directory submissions. In certain AI search contexts, off-page tactics, like creating press releases or being cited on article directories, can cause RAG systems to index multiple instances of your content, increasing the likelihood of snippet selection.
In my short YouTube video, I demonstrate how these tactics, some of which may be called “spammy”, can boost visibility in AI-based searches by flooding the retrieval index with relevant signals. While this approach carries risks in traditional SERPs, it can yield surprisingly effective results in AI-driven environments—so long as you monitor for negative user feedback or credibility issues.

FAQs
What is the difference between RAG and a standard LLM response?
A standard LLM generates answers based solely on its pretraining data, which may be outdated if trained months ago. RAG, by contrast, performs a real-time search of external documents before generating an answer, ensuring the information is up-to-date and grounded in factual sources.
Can I use RAG to search proprietary company files?
Yes. By connecting a RAG-enabled system to your internal knowledge base—such as a SharePoint repository or a private document store—your organization can get highly specialized answers rooted in proprietary data without retraining the entire model.
How do schema markup and structured data help AI retrieval?
Schema markup like FAQ Page or How To tells AI crawlers exactly where Q&A pairs and step-by-step instructions begin and end, so retrieval engines can extract self-contained snippets without scanning the entire page. This increases the chances of your content being quoted verbatim in AI-generated summaries.
Checklist
-
- Identify and segment core Q&A snippets with clear semantic headings.
-
- Embed date-stamped, authoritative citations (e.g., government or peer-reviewed).
-
- Use conversational, question-style headings and varied synonyms.
-
- Apply FAQ Page or How To schema markup around structured content.
-
- Ensure fast load times, mobile optimization, and valid XML sitemaps.
-
- Monitor AI search analytics to track snippet performance and update.
-
- Experiment with off-page snippet postings; measure AI retrieval impact.
Brief Summary and Conclusion
Modern AI search engines and LLMs harness RAG workflows to merge external data retrieval with text generation, often producing answers that are highly accurate and current. By structuring content with clear semantic headings, embedding up-to-date citations, using natural-language Q&A phrasing, and applying FAQ Page or How To schema, you make it easier for AI retrieval to spot—and quote—your material without resorting to a virtual game of hide-and-seek.
Building topical authority, maintaining strong technical SEO, and even testing off-page snippet tactics can further boost your visibility in AI-driven searches. As AI search evolves, continually monitoring and adapting your strategy will be crucial for long-term success in the RAG-powered landscape.