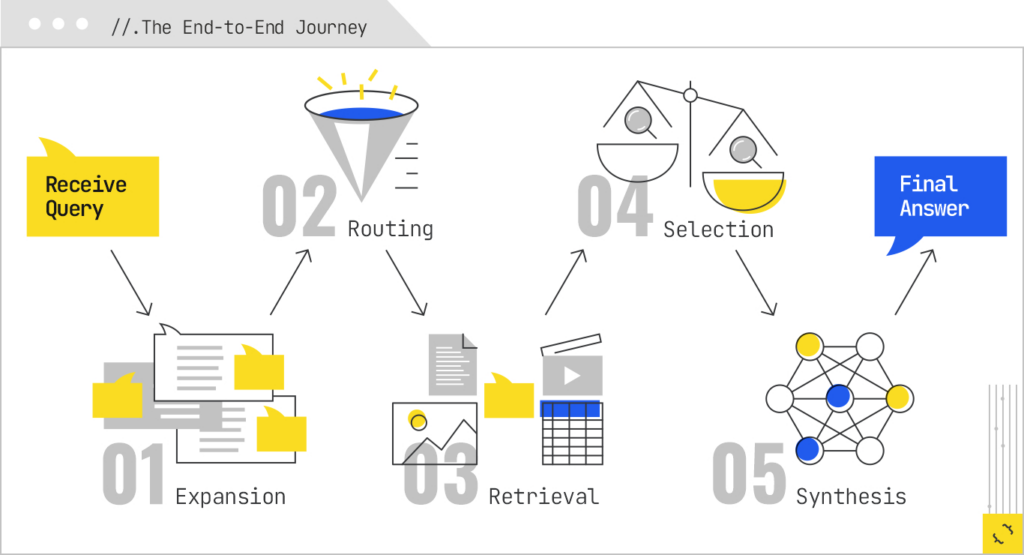
The New Local SEO Reality: AI Up Top, Trust Still Underneath

If you want the short version, here’s what I’m seeing right now. Local SEO is still very much alive, but the way people discover and choose local businesses is changing. Google is moving toward a more conversational, AI-engine experience, so it’s not enough to just rank anymore. Your business also needs to be easy for Google to understand, easy for AI systems to summarize, and easy for real people to trust.
I recently sat down with Darren Shaw from Whitespark, and the conversation reminded me why local SEO is still one of the most valuable parts of search.
Darren has been in this space long enough to see local search evolve from simple map pack tactics into a much more sophisticated system of proximity, relevance, reviews, business data, and now AI recommendations.
That kind of perspective matters to me. A lot of people in SEO get distracted by the latest acronym or trend, but what I appreciate about Darren is that he has seen enough cycles to know what actually holds up over time.
The main takeaway of the conversation was pretty simple. AI is changing the way people experience search, but it is not replacing strong local SEO fundamentals. If anything, it is making them even more important.
The local search interface is changing
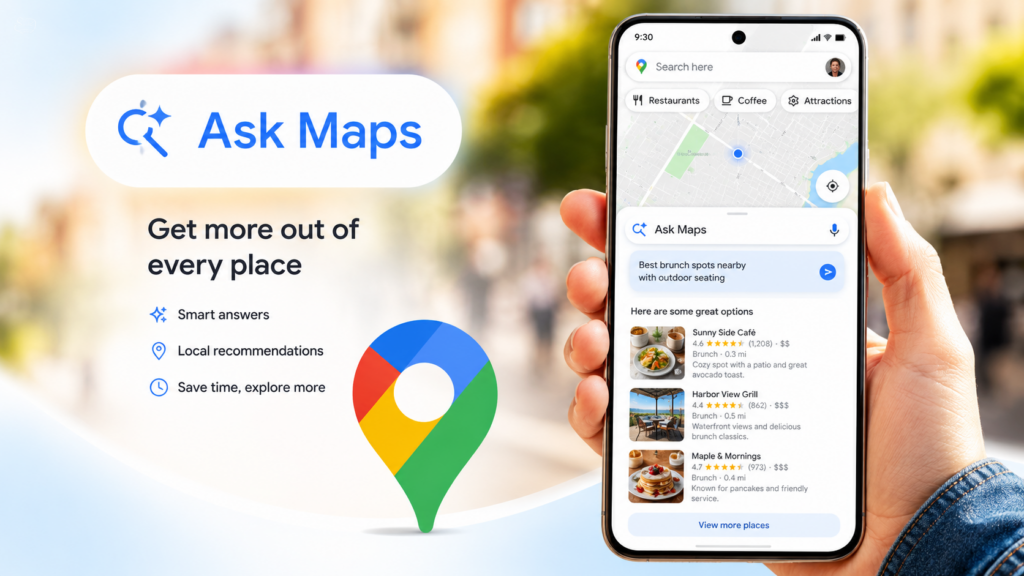
The local search interface is changing because people are no longer limited to short keyword searches like “plumber near me” or “dentist Dallas.” They are asking longer, more specific questions. They want recommendations based on urgency, preference, trust, location, availability, and context.
That changes the job of local SEO.
For a long time, local SEO was mostly about ranking in the local pack for short keywords. I still think that matters. I just don’t think it tells the whole story anymore. In an AI search environment, the bigger question is whether the system understands your business well enough to recommend it in the right situation.
That’s why I think Google’s Ask Maps feature matters. Google is turning Maps into a Gemini-powered conversational experience where people can ask real-world questions about places and get personalized recommendations based on Maps data. To me, that’s a pretty clear signal. Maps is becoming more than a directory. It’s becoming an AI search layer that helps people make real-world decisions.
When I look at a search like finding a nearby dentist who is good with anxious patients and offers evening appointments, I see a very different kind of intent than a simple “dentist near me” search. The practice that wins that query is usually not just the one closest to the person searching. It is the one with the clearest service information, the strongest reviews, useful supporting content, and enough trust signals that Google feels confident recommending it.
That’s where local SEO is headed.
Local SEO was never just about ranking
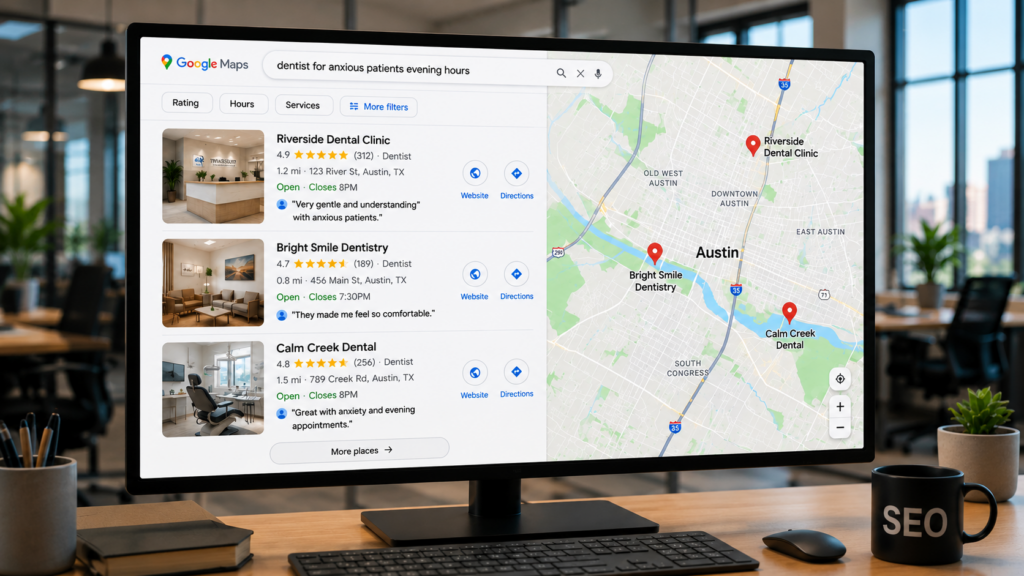
I never viewed local SEO as just a rankings play. A local business does not win because it shows up. It wins when someone chooses it. Rankings give you visibility. Selection is what turns that visibility into revenue.
That’s where I see a lot of businesses get stuck. They obsess over where they appear and ignore how they look when a real customer starts comparing options. You can rank well and still lose the lead if your Google Business Profile feels thin, your reviews do not build trust, your photos look outdated, or your service details do not answer the question the buyer actually has.
That matters even more now because AI-driven local search is not just about retrieving businesses. It is comparing them. It is summarizing them. It is trying to decide which option looks most useful for the person searching.
So when I look at local visibility, I want a business to be built for both retrieval and preference. Retrieval means Google can find it and understand it. Preference means the system has enough confidence to show it as the better fit. That’s the standard I care about.
Reviews are one of the strongest trust layers in local SEO

I think reviews are one of the strongest trust layers in local SEO because they influence both rankings and conversions. Darren made that point clearly in our conversation, and I agree with him completely.
A lot of business owners still think about reviews as reputation management. That is part of it, but it’s not the whole story. Reviews are also content. They capture the real customer experience in natural language. People talk about services, staff, neighborhoods, problems, outcomes, wait times, pricing concerns, and the reasons they chose that business in the first place.
That kind of language helps customers decide, but it also helps search systems understand the business at a deeper level.
If patients keep saying a dental office is great with nervous patients, that is a meaningful signal. If homeowners keep mentioning emergency roof repair after storms, that matters too. If restaurant customers keep bringing up gluten-free options, fast service, parking, or atmosphere, that gives useful context.
I think this matters even more in AI local search because the query is getting more conversational. People are not just searching for a category anymore. They’re looking for the right fit.
Review recency matters more than most businesses realize
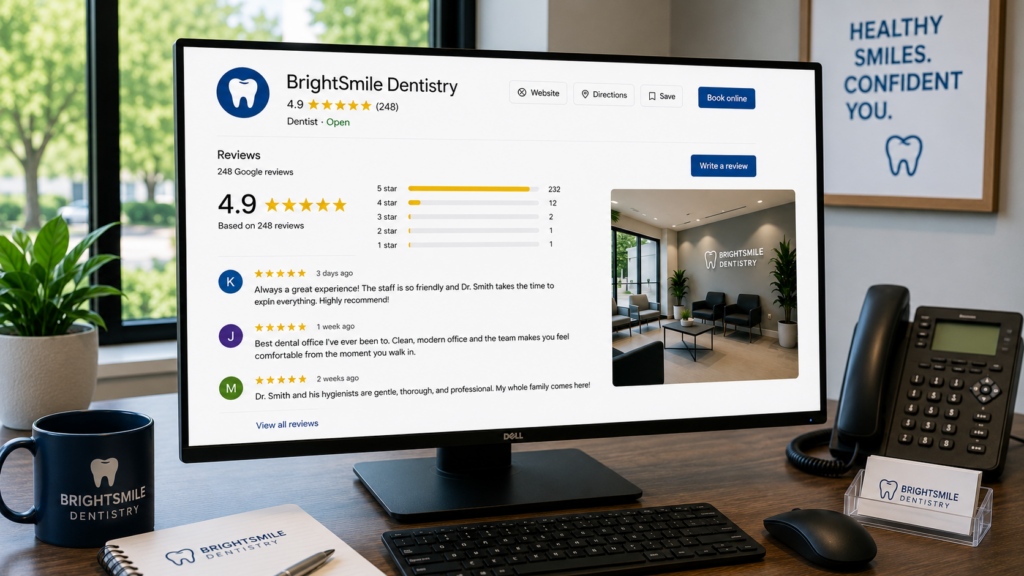
Review recency matters more than most businesses realize because customers and search systems both care about what’s happening now. A business with a large review count but no recent activity can look stale. A business with fewer total reviews but consistent new reviews can look active, trusted, and relevant.
That does not mean businesses should chase reviews in a sloppy or aggressive way. It means review generation should become part of the operating process. Ask at the right time. Make it easy. Train the team. Use a simple review link or QR code when appropriate. Follow up naturally. Keep the process tied to real customer experience.
The mistake is treating reviews like a one-time campaign. Reviews should be a steady signal that the business is active, trusted, and still delivering.
That is especially important in competitive local markets where every business claims to be the best. Reviews give buyers and AI systems a stronger reason to believe one business over another.
Your Google Business Profile has to be built like a conversion asset

I look at a Google Business Profile as a conversion asset, not a box to check. A lot of local buyers decide who to call before they ever spend much time on a website, so the profile itself has to help you win the click, the call, or the visit.
That is one reason local SEO has been more protected from AI disruption than pure informational SEO. If someone wants a definition or a basic how-to answer, AI may handle that without sending the user anywhere. But if someone needs a dentist, lawyer, plumber, med spa, restaurant, HVAC company, or roofer, they still have to choose a real business.
And a lot of that choice happens inside Google.
Your categories, services, products, photos, reviews, posts, hours, attributes, and business description all shape that decision. Some of those elements can affect rankings. Others do more of the conversion work. I care about both.
I see too many businesses treat their Google Business Profile like a one-time setup task. They choose a category once, add a few photos, write a generic description, and move on. Then they wonder why competitors with stronger profiles keep getting the calls.
That’s not how I approach it.
If your profile is one of the main places customers compare you, it needs to be built intentionally and managed like a living visibility asset.
Categories can quietly make or break local visibility

Categories are one of those local SEO details that seem small until they start costing a business real visibility. I check them early because they tell Google what kind of business it is. If the primary category is too broad or just not aligned with the core offer, you can create a relevance problem before anything else even gets a chance to help.
I see this a lot. A law firm selects “law firm” when the better fit might be personal injury attorney, criminal justice attorney, or bankruptcy attorney. A dental practice might not reflect the services it actually wants to be found for, which means it can miss visibility for higher-intent searches tied to emergency dentistry, cosmetic dentistry, implants, or orthodontics.
This is one of the first things I look at in a local SEO audit because it’s simple, but the impact can be significant. The primary category needs to match the main thing the business wants to be found for. Then the supporting categories, services, website content, reviews, and citations all need to reinforce that same relevance. That’s how I help close the gap between what a business offers and what Google understands.
Citations are still useful, but they are not a magic shortcut

Citations still matter, sure, but I don’t look at them as the shortcut they used to be in local SEO.
I think of them as trust and legitimacy signals.
If a business only shows up on its website and Google Business Profile, that’s a pretty thin footprint. If the same business information shows up consistently across major directories, industry platforms, local sources, review sites, and other trusted third-party profiles, the business looks more established and easier to verify.
I think that matters for Google. I also think it matters even more as AI systems take a bigger role in local discovery.
What I would not do is push a business into hundreds of weak directories just to inflate the count. I would focus on building a clean, consistent presence in the places that actually matter. That usually means major business directories, relevant local sites, industry-specific platforms, review sources, and professional associations.
The right mix depends on the business. If I am working with a lawyer, I am looking at legal directories. If it is a dentist, I want healthcare-related profiles. If it is a home services company, I am thinking about home services platforms, local associations, and trade directories.
I am not after volume here. I am after confidence.
AI local search rewards complete information

AI local search rewards complete information because conversational searches need more context.
A short keyword search might only need a service and a location. But if someone is looking for the best emergency plumber nearby who can come out tonight and has strong reviews, the system has a lot more to evaluate. It has to understand the service, the urgency, the area, the availability, the review quality, and whether the business looks trustworthy.
If your business does not communicate those details clearly, you are asking Google and AI tools to fill in the blanks. I do not like building marketing strategies around guesswork. I would rather feed the system better information.
That starts with the basics. I want the website to answer real buyer questions. I want the Google Business Profile to list clear services. I want reviews that are recent and specific. I want citations to stay consistent. I want photos that build trust. And I want the content to explain who the business helps, what it does, where it works, and why someone should choose it.
This is not about stuffing keywords into every surface. It is about making the business easier to retrieve, understand, compare, and recommend.
That is the difference I see between old local SEO and local SEO built for AI search.
Old SEO tactics are not enough by themselves

Old SEO tactics are not enough on their own anymore, especially in local search. Google is doing more than matching words. It’s getting more interpretive. It’s trying to understand the business itself, the context around the search, the evidence behind the claims, the sentiment around the brand, and whether the fit is actually right for that customer’s need.
That does not make traditional SEO useless. I still care about the fundamentals. Technical health matters. Crawlable pages matter. Strong content matters. Internal linking, backlinks, local relevance, and clean business data all still do real work.
But now I see those pieces as support for something bigger.
I am not just asking if a business can rank for a keyword. I am asking if Google would feel confident recommending that business for a specific situation.
That shift changes how I approach local strategy.
A generic service page is not enough. A thin Google Business Profile is not enough. A few old reviews are not enough. A list of locations without real local proof is not enough.
If a business wants to win, it has to become the clearest and most credible answer for the situations it wants to own.
That’s the work.
The biggest opportunity is fixing selection, not just visibility

The biggest opportunity is fixing selection, not just visibility. Most businesses want more rankings, but many of them are already leaking leads from the visibility they have.
If your profile gets impressions but few calls, that is a selection problem. If people click your profile but choose a competitor, that is a selection problem. If you rank locally but your reviews, photos, services, and website do not build confidence, that is a selection problem.
This is why I don’t separate SEO from conversion.
A stronger review profile can improve trust. Better photos can reduce hesitation. Clearer services can increase relevance. Better website content can support both users and AI systems. Stronger citations can reinforce legitimacy. A better Google Business Profile can turn more visibility into actual leads.
That is how local SEO should be judged.
Not just “Did rankings move?”
The better question is, “Did the business become easier to find, trust, and choose?
Local SEO is getting more conversational, more personalized, and more influenced by AI, but the goal is still the same. I want the right customers to find your business, trust what they see, and feel confident choosing you.
What has changed is the standard. If you want to show up well in AI local search, your business needs complete information, recent reviews, accurate categories, clear service details, consistent listings, and content that answers the real questions people ask before they ever contact you.
If you want a practical game plan, schedule a call with me. I’ll show you where your local visibility is leaking, what is keeping your business from being preferred, and which fixes I would prioritize first.