The llms.txt debate: what’s real, what’s hype, and how to use it (safely)

Short version:
llms.txt is a proposal, not a formal web standard. Some sites ship it; some AI tools and SEO plugins promote it. Google says you don’t need it to show up in AI Overviews or any other Google products.
But: …like any public .txt file, an llms.txt URL can be crawled and indexed, so in rare cases a bare, unstyled text page could show up in search instead of your real, designed page.
I know of someone who created a playful file called cats.txt to make a simple point: Google can index plain text files if they’re publicly accessible and discoverable. In other words, the name doesn’t matter, if it’s a .txt and reachable, it can show up in search, just like any other indexable file type.
If a text file is publicly visible on your site, search engines can list it, which you certainly don’t want. To prevent this, send X-Robots-Tag: noindex in the HTTP response (works for non-HTML files), and if you want to point search engines to the right page, add a Link: <https://your-page>; rel=”canonical” header. Here’s what a real plain-text doc looks like in a browser (the kind that could hypothetically rank if you don’t block indexing):
https://developers.cloudflare.com/llms.txt.
Google’s documentation covers both the noindex response header for non-HTML resources and using an HTTP canonical header.
Below is a clear walk-through, first in plain English (with analogies), then the technical details and safest practices.
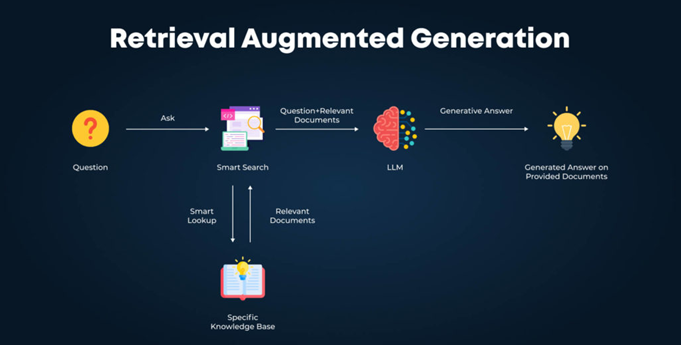
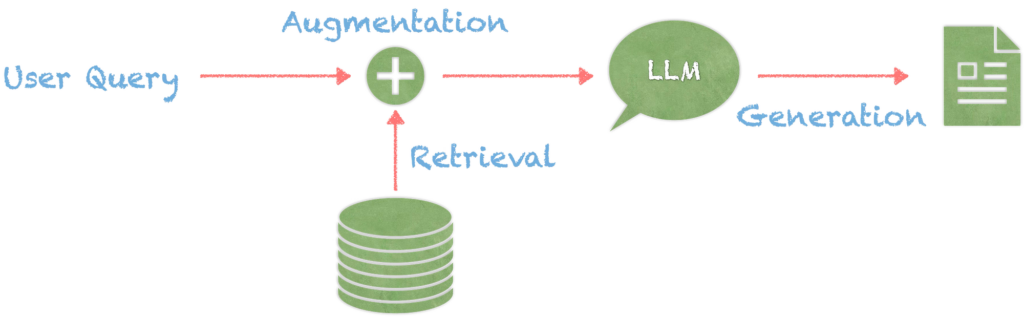
What is llms.txt?
llms.txt is a simple text file you put at example.com/llms.txt. The file lists or summarizes your most important pages in Markdown, so AI systems can more easily read and use your content. Think of it like a cheat-sheet menu for bots: “Here are the dishes you should try; here’s how to ingest or interpret them.” It’s inspired by robots.txt and sitemaps, but it isn’t an official protocol like those are, just a community proposal.
Today, there’s no universal adoption. A directory of live implementations shows many developer-tooling/docs sites experimenting, often paired with a bigger llms-full.txt that expands the content.
John Mueller / Google’s stance: In a conversation with Caleb and a few other colleagues, Google’s John Mueller made it clear what side of the debate he’s on. You don’t need llms.txt; the guidance is to keep following normal SEO practices.
Why is there a debate?
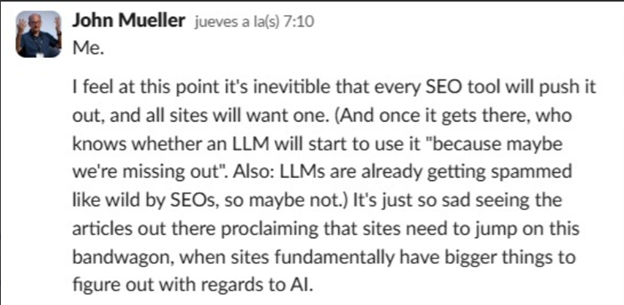
The “we don’t need this” camp
- Google says it won’t use llms.txt for AI search results, so for many sites this is optional at best.
- llms.txt isn’t a standard; support and behavior differ by bot. In other words, don’t expect consistent results.
The “we’re seeing activity in the wild” camp
- Practitioners have shared examples and logs showing Google indexing llms.txt pages, alongside surges of bot hits when large platforms roll it out, because it’s just a public text file like any other.
- That doesn’t prove Google uses llms.txt for AI search results. It only proves that public .txt files can be crawled and indexed, which Google’s docs have said for years.
A layperson’s guide to the technical bits
- robots.txt vs noindex
robots.txt is like a bouncer who tells certain crawlers not to walk certain halls. It doesn’t guarantee your URLs won’t show up in the search phone book (the index). Pages blocked in robots can still be indexed by URL if they’re linked elsewhere. If you truly don’t want a URL in the index, use noindex, that’s a separate rule delivered in HTML or HTTP headers. - X-Robots-Tag and canonical
For non-HTML files like .txt, the right place to control indexing is the HTTP response header.- X-Robots-Tag: noindex = “don’t list this address in Google.”
- Link: <https://example.com/page>; rel=”canonical” = “if you do need to reference this, use our public address here.” (Google supports canonical in the header for non-HTML formats.)
- User-Agent/UA and why blocking by UA isn’t enough
“UA” is the name badge a crawler shows at the door (e.g., Googlebot, GPTBot). You can write per-UA rules in robots.txt, and major AI vendors document their UA strings.
But name badges can be forged; to be sure a request is truly a vendor’s bot, verify by reverse-DNS/IP, not just the UA string. Cloudflare has even accused some AI crawlers of stealth crawling (changing badges and IPs).
- “Cloaking” and dynamic rendering
Serving different content to bots than to users is a slippery slope. Google considers cloaking a spam tactic when bots and users see materially different things. Google also deprecated dynamic rendering (bot-only HTML) as a long-term approach. If you want a bot-friendly version, keep the substance the same as what people see.
The cannibalization risk (and how to avoid it)

Imagine your llms.txt ranks for a branded query. A searcher clicks and lands on a wall of plain text with no design, navigation or conversion paths. That’s the risk: poor UX and lost revenue. It’s not hypothetical, plain text files do get indexed, and practitioners have shown real examples of llms.txt and llms-full.txt pages in the index. We also showed an example earlier in this article.
Fix: keep llms.txt fetchable (so AI tools can read it) but non-indexable in web search with:
X-Robots-Tag: noindex
Link: <https://www.example.com/your-preferred-page>; rel=”canonical”
These are HTTP headers on the llms.txt response, not tags inside the file. This is the safest, standards-compliant way to prevent cannibalization while still letting crawlers pull your file.
If you still want to experiment: safest practices

1) Treat llms.txt as optional, and experimental
Ship it only if it supports real goals. Keep expectations modest; it’s a proposal, not a protocol.
2) Prevent web-search cannibalization
Serve HTTP headers on llms.txt (and llms-full.txt if you publish one):
- X-Robots-Tag: noindex
- Optional: Link: <https://www.example.com/the-main-URL>; rel=”canonical”
Think: “Please don’t list this file in the phone book; if you must reference something, here’s the main storefront.”
3) If you want to block certain AI crawlers elsewhere, do it the right way
- In robots.txt, write rules per UA (e.g., User-agent: GPTBot). Vendors like OpenAI document their bot names.
- For high-stakes data, verify IPs (reverse-DNS) because UA strings can be faked. Google documents how to verify Googlebot; similar logic applies to others.
- Be aware: some AI bots have been accused of ignoring robots.txt or crawling stealthily, so consider edge-level blocking if needed (WAF/CDN).
4) What to put in llms.txt (if you use it)
Link to canonical, public pages that you want AI systems to cite: FAQs, policies, product specs, pricing explainer, and key how-tos. Keep it concise; don’t dump the whole site.
5) Instrumentation & monitoring
- A .txt file is just raw text. Web browsers don’t run code inside it, so you can’t drop a JavaScript analytics snippet (like GA/GTAG) into a .txt and expect it to fire. Browsers only execute scripts when the content is served as a script/HTML type, not text/plain.
If you still want to see who’s fetching that file, look at your server or CDN access logs. Those logs list every request (time, IP, user-agent, URL, etc.), so you can count hits to /llms.txt even without JavaScript. Examples: Apache’s access log and Cloudflare Logs.
- Watch Search Console: if a text file starts appearing in “Indexed,” revisit your headers. Google’s docs confirm indexing can occur even without crawling the content (e.g., when discovered by links).
6) Don’t block JS/CSS for Googlebot
If your SEO defense plan includes blocking scripts to hide unique content from AI, be careful: blocking JS/CSS broadly can break rendering in Google Search. If you must, target AI bots individually, not Googlebot
The bottom line (for decision-makers)

- Not required: Google’s AI Mode doesn’t depend on llms.txt; normal SEO still wins.
- Not a standard: It’s a proposal with uneven support. Useful for experimenting, especially for docs-heavy products; not a silver bullet.
- If you try it, ship it safely:
- Put it at the root.
Keep it short and link to your best pages.
Send X-Robots-Tag: noindex and, if helpful, a header canonical.
Keep content parity; avoid UA-based “special versions” that diverge.
- If you must block certain AI bots elsewhere, use per-UA robots rules plus IP verification at the edge; be aware of stealth crawlers.
- Put it at the root.
If you want a place to start, you can base your evaluation on current adoption (developer docs ecosystems, directories of live files) and any internal log evidence you have about bot hits to llms.txt. Then decide whether it’s worth maintaining a curated cheat-sheet for AI, or whether your time’s better spent doubling down on structure, internal links, and copy, the proven levers. SEO Rank Media is among the leaders in the AI search conversation. Reach out to explore how we can set your brand up for the future.